
Google has taken AI-generated images to a new level with Imagen.
Imagen is a new state-of-the-art text-to-image diffusion model capable of generating highly realistic images given text input. It uses a very powerful language model, T5–XXL a language model with 4.6 billion of parameters trained on a huge text-only dataset.
This new model is not only able to generate better and more photorealistic images, but also the images generated by Imagen match the quality of real images that are present in the COCO dataset.
The Google researchers also proved that they can both increase the fidelity and the image-text alignment of the images by simply using larger language models that are much cheaper to train since they rely simply on text-only data.
Yet Google decided not to make the demo and source code public due to serious concerns as
generative methods can be leveraged for malicious purposes, including harassment and misinformation spread, and raise many concerns regarding social and cultural exclusion and bias.
Before we get into details, let’s just clear some of the jargon.
What is a diffusion model?
A diffusion model is a new approach for synthesizing photo-realistic images that rival GANs.
To understand how diffusion models work, let’s consider an example.
Consider the image of a Cherry in Blossom as seen below:

And then imagine that we apply noise systematically to this image using a noise function such as the Gaussian noise function, until we obtain an image like the one below:

We can hopefully all agree that the information in the original image is lost. But, if we are told that this image contains a Cherry Tree blossom, we can in theory recreate the image of the tree by using a little bit of imagination and skill. Here is my attempt at drawing the original image:

Okay, I am not an artist. But if I asked a real artist to reconstruct the cherry tree in the image, maybe, she could come up with something like this:

Not really photo-realistic, but anyone should be able to identify the painting as a Cherry Tree in blossom.
The reason the artist is able to do that is that the artist was trained in the art of landscape drawing.
How a Diffusion model is trained
To train a diffusion model we train it by first adding Gaussian noise to thousands of images using a step-by-step process of adding noise until we get to something as close as possible to isotropic gaussian noise. This iterative process of adding noise is done in thousands of small steps.

The generative process of learning takes place when we challenge the diffusion model to remove the noise in order to reconstruct the original image.
The reality is that it’s impossible to reconstruct the original image, and this is where the magic takes place. As long as the diffusion model is trained on the type of object we are trying to reconstruct, like an artist it will be able to create a photo-realistic image of a Cherry Tree in Blossom, hence why the diffusion model is called a generative model.

The model is trained on how to reconstruct images of different classes by applying Gaussian noise to real images in a step-by-step manner until we get something as close as possible to isotropic gaussian noise!
And then to achieve the image generation, we train a neural network until it learns how to remove the noise from the image until we something as close as possible to the object class of the original image.
The building blocks for Imagen
Now that we have a basic understanding of what diffusion models are, let’s look in more detail at the architecture used in Imagen. Imagen is not just about the generative diffusion model. There are several building blocks.
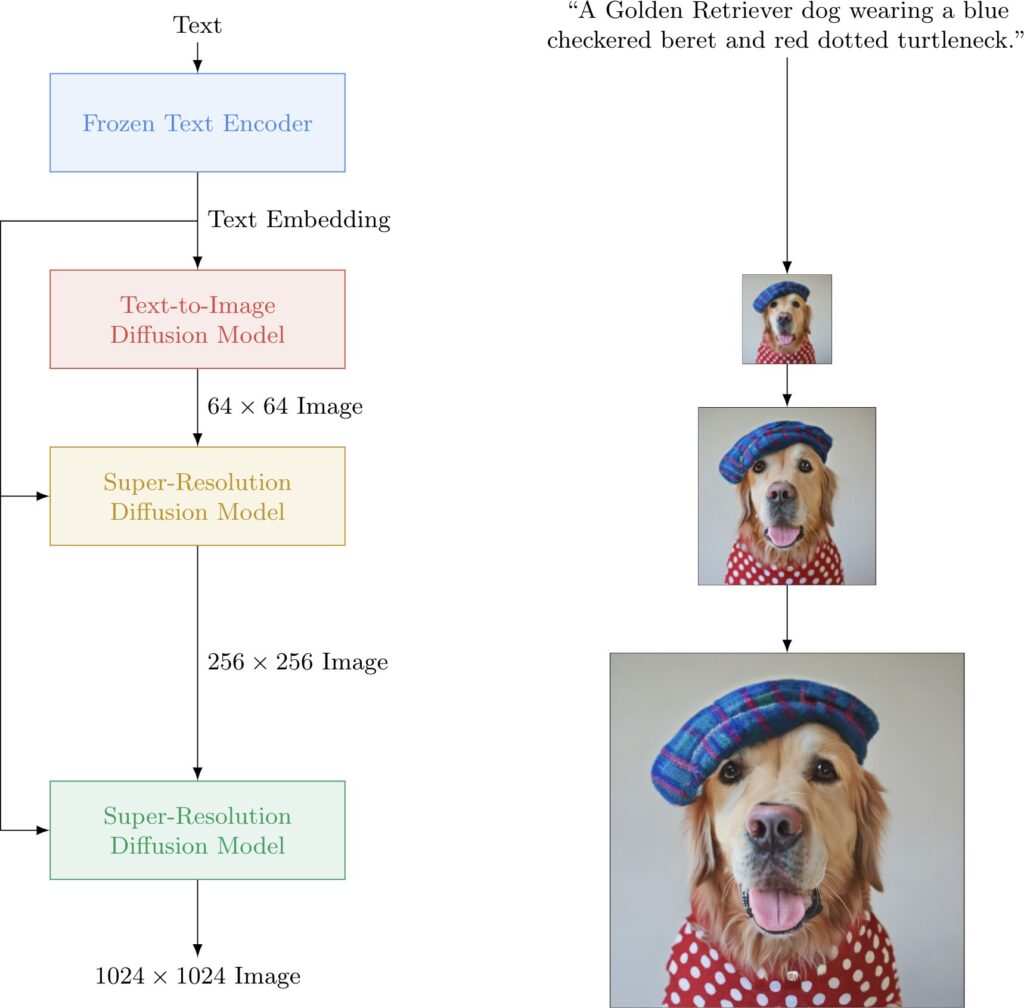
Imagen makes use of a powerful language model that converts a visually descriptive text to a set of text embeddings that contain visually rich information about the image that needs to be generated. Note that the language model is never trained on image data. It is a pure text-only language model.
Once the language model produces text embeddings, these are passed to a text-to-image diffusion model that produces images of size 64×64. This model is trained with a Google internal dataset and with the LAION-400M open-source data set. This data set contains 400 million image-to-text pairs with the text embeddings being generated by CLIP.
Since the images produced by the text-to-image diffusion model are rather small, Imagen uses a cascade of two super-resolution diffusion models to increase the size of the image, up to 1024×1024.
But what is truly innovative about Google Imagen, from a machine learning point of view?
Use of frozen pre-trained language Models
First, it uses frozen pre-trained language models(BERT, CLIP, T5-XXL) which have been trained on text data only. The advantage of using text-only models is that these models can be very large as there is a lot more text-only data available to use to train the model.
Improvements to the Diffusion Model
Imagen also is able to generate higher quality images because of improvements in its diffusion model, such as the use of dynamic thresholding instead of static thresholding during the training of the model. It also introduces a new simplified neural network architecture called Efficient U-Net, which converges faster and requires less memory usage.

Source: Google
Another of the contributions highlighted in the paper is a new evaluation benchmark called DrawBench which uses human feedback. The requirement for this new type of benchmark is because the existing benchmarks available e.g. COCO FID, etc don’t seem to evaluate well the alignment between the image and the text. Meaning that they miss the nuances that we humans don’t normally miss.
The Google researchers figured out that even though the results of their model looked superior to previous image generation models. the benchmarks were not picking this up. So how did they solve that problem? They created DrawBench, a new benchmark based on a suite of structured text prompts for text-to-image evaluation.
Training Machine Learning Requirements
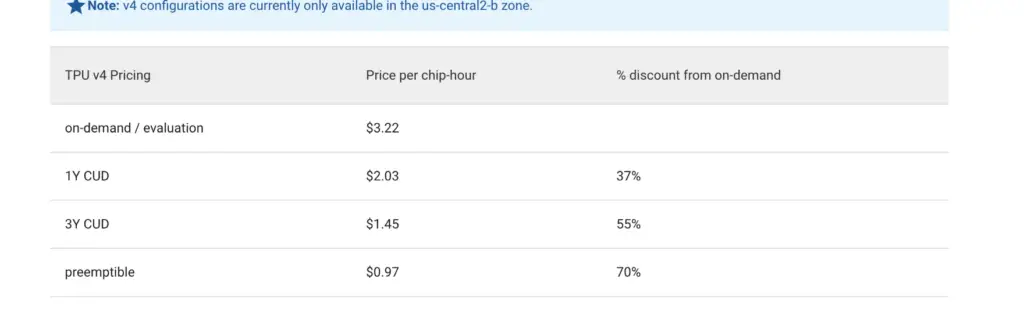
As one might imagine, it is not going to be cheap to train a model with this many parameters, and you are right on the money. To train Imagen it took 256 x TPU-v4 chips to train the basic image generation model, and 128 xTPU-v4 chips. However, I couldn’t find in the paper any information on how many hours it took to train this model.
But based on the list pricing for TPU v4 chips, it cost about $1236/hour to train the model. Assuming that Google didn’t want to commit to 3 years to get the heavy discounts 😉
But it seems to me that these far fewer resources than what was required to train DAL-E by OpenAI, which used 1024 x Nvidia A100 with 16GB of GPU memory each. I wonder how many GPUs were used to train DAL-E-2? Unfortunately, I couldn’t find that information in the new paper for DAL-E-2.
Why did Google not provide the source code and demo?
As I mentioned earlier in this article, Google has serious concerns about how people could abuse Imagen to generate the wrong kind of images with malicious intent.
But perhaps the main reason for this fear, is due to the LAION-400M dataset being known to contain inappropriate images.
The LAION-400M is one of the few open-source datasets available and since we are talking about 400 million images it was gathered using web scraping tools and automatically annotated with text embeddings using CLIP.
As stated in the Github page for CLIP:
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3.
https://github.com/openai/CLIP
Conclusion
There is certainly progress being made, and in the near future, we will all be able to create unique stock photos with a few keystrokes!
Hopefully, Google will find a way to censure Imagen so that we all can try it soon!
Resources
Papers
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding”, Chitwan Saharia , W. Chan, S. Saxena , L. Li, J Whang, E. Denton, S. Ghasemipour, et al,
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs, Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, Aran Komatsuzaki
Related
Google Imagen Website
https://imagen.research.google/
Improving Diffusion Models as an Alternative To GANs, Part 1
https://developer.nvidia.com/blog/improving-diffusion-models-as-an-alternative-to-gans-part-1/
OpenAI DAL-E Demos
https://openai.com/dall-e-2/#demos
Demo of DAL-E Mini
https://huggingface.co/spaces/dalle-mini/dalle-mini