If you have read my last article on GANverse3D, then you will probably have heard about the DIB-R paper, which I mentioned a few times. This was a key paper for 3D Deep Learning from 2019.
The DIB-R paper introduced an improved differential renderer as a tool to solve one of the most fashionable problems right now in Deep Learning.
To generate 3D objects from a single 2D image.
When the DIB-R paper was released, back in 2019, it also included source code. But unfortunately, it was missing the machine learning model that was needed to run that code.
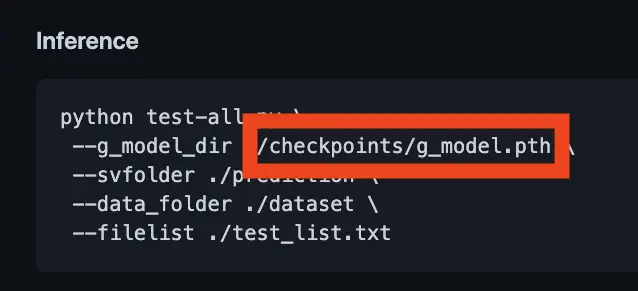
This was quite disappointing since I really wanted to try this first-hand.
The good news is that we can now try DIB-R first hand because Nvidia has released a PyTorch library part of Nvidia Kaolin which includes DIB-R, the same differential renderer that was used in the DIB-R paper.
But best of all, the library, also includes a tutorial that showcases the capabilities of DIB-R, the differential renderer.
When I first saw the tutorial, I must confess that I didn’t really understand it much. Also, I was not even sure why a differential renderer is even needed in the first place. And I even confused the differential renderer with the neural network described in the DIB-R paper, that is capable of generating a 3D object from a single 2D photo.
They are two separate things actually.
So in this tutorial, I am going to show you step by step how to try the DIB-R tutorial, and also I will share with you what I have learned about DIB-R and the field of 3D Deep Learning.
What is Nvidia Kaolin
Nvidia Kaolin is not just about the PyTorch library. Nvidia Kaolin has two main components:
- Nvidia Omniverse Kaolin App, is an application created by Nvidia to help 3D Deep Learning researchers by providing a visualization tool for 3D datasets, a means of generating synthetic datasets and even comes with the capability of visualizing the 3D outputs generated by a model during training.
- Nvidia Kaolin Library, a PyTorch API, that supports different 3D representations, like point clouds, mesh, and voxel grids, and functions that allow conversion from one representation to the other(kaolin.ops). The library also includes DIB-R, the differential renderer(kaolin.render), functions to load data from popular 3D datasets like Shapenet, functions to load 3D models in different file formats, like obj and usd(kaolin.io). An API to create 3D Checkpoints(kaolin.visualize) and in the future a lot more.
The DIB-R tutorial
Required Software
- Hardware: Nvidia GPU
- Operating System: Windows or Linux
To be able to run the DIB-R tutorial you will need to have:
Required software:
- Python 3.7
- Pytorch 1.7.0
- CUDA 11.2 or above
- Nvidia Kaolin Library
- Nvidia Omniverse Launcher
Using Anaconda
We can ease our pain so much by using Anaconda. With Anaconda, it’s easy to install multiple versions of Python, and with the use of virtual environments, we can greatly reduce the chances of finding incompatible versions of a library.
If you don’t have Anaconda installed, you can follow this article to complete the Anaconda setup.
CUDA
Before installing anything, check that you have CUDA version 10.2 or above installed. If you don’t, you might want to read one of my recent articles in which I show you how to install CUDA 11.2.
Creating Conda Environment
Let’s start by creating a Conda environment for everything that we need to install. Let’s call it kaolin
$ conda create --name kaolin python=3.7
$ conda activate kaolinDownloading Nvidia Kaolin from Github
In preparation for our setup, we are going to download Nvidia Kaolin from Github.
git clone --recursive https://github.com/NVIDIAGameWorks/kaolin
cd kaolin
Which release of Kaolin to use
The Kaolin installation instructions tell us to switch the git branch to the latest release of Kaolin, which as of today is v0.9.0. Unfortunately, release 0.9.0 doesn’t include yet the DIB-R tutorial. The DIB-R tutorial is only in the master branch.
For that reason, we are going to do the Kaolin setup directly from the master branch.
Install Pytorch 1.7.1
Before we can install Nvidia Kaolin, we need to install PyTorch.
To make things really easy, let’s install Pytorch with Conda:
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 -c pytorchInstall Nvidia Kaolin App
Before we try to run the DIB-R tutorial, although not strictly required, it is preferable to install the Nvidia Kaolin App.
The Nvidia Kaolin App is going to help us visualize the 3D model, in this case, a clock, that we are going to train DIB-R with. And it is also going to help us visualize the wider dataset from where this clock comes from.
We will also use this tool later to generate more training data for another 3D asset, which we will pick from the kitchen dataset.
Install Nvidia Omniverse Laucher
Before being able to install Nvidia Omniverse, we first need to download and install the Nvidia Omniverse Launcher. The video below, from Nvidia, shows you the exact steps.
Install Nvidia Kaolin App from the Nvidia Omniverse Launcher
Now that Nvidia Omniverse is installed, we can install Nvidia Kaolin App.
Lets open the Nvidia Omniverse Launcher and select the EXCHANGE tab.
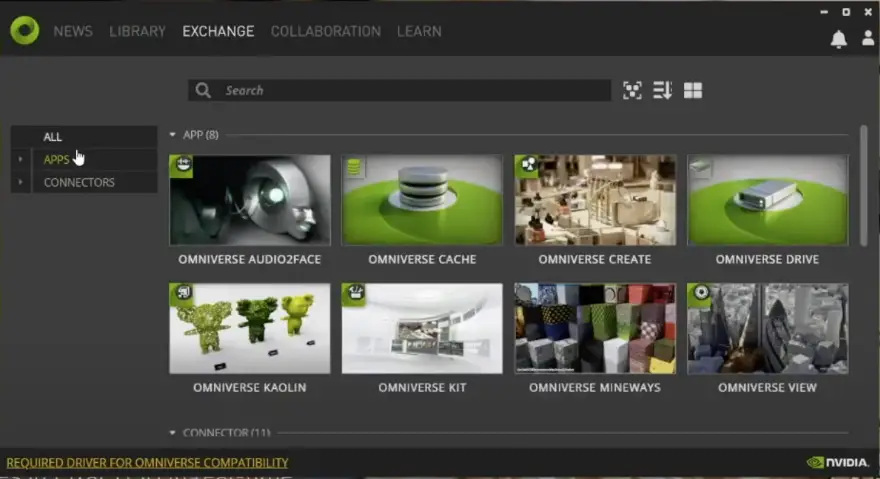
Then we click APPS and search for Kaolin. You can then download and install the Omniverse Kaolin App from here.
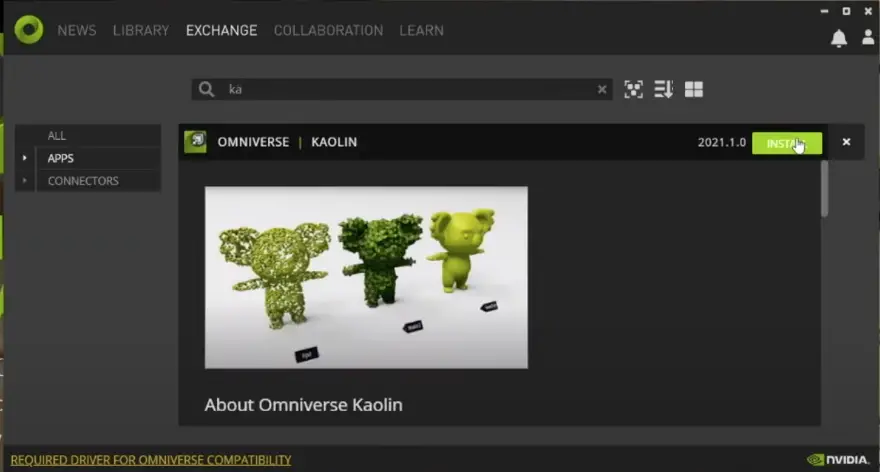
Putting DIB-R into context
Now that we have installed all the components, we are ready to try the DIB-R tutorial!
But before that, let’s briefly talk about the recent GanVerse3D and DIB-R papers, and how they are connected.
In the first part of the DIB-R paper, Nvidia details the design of an improved differential renderer, called DIB-R.
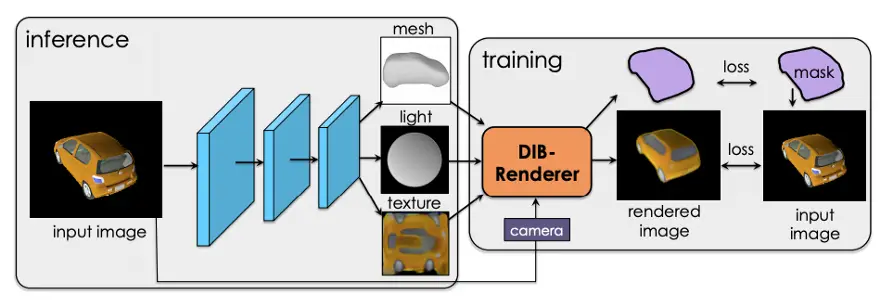
In the second part, the DIB-R paper discusses how to use DIB-R, the differential renderer, to solve difficult problems in 3D Deep Learning: To train a model capable of predicting 3D object shape, texture, and lighting from a single image. In this case, the model was trained using data from the ShapeNet and CUB Bird dataset.

In the follow-up GANVerse3D paper, Nvidia goes up one notch.
Instead of using the ShapeNet datasets and the CUB bird dataset, they use datasets generated by using StyleGAN-R and a new GAN, called DatasetGAN.
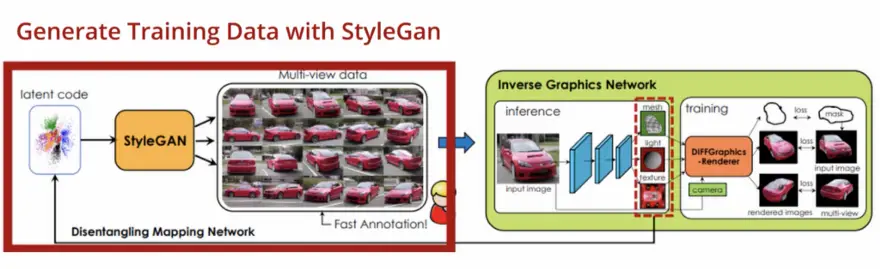
StyleGAN-R, aka StyleGAN renderer, is just like a normal StyleGAN, except that its first four layers are frozen to produce images of the same object class in different perspectives with a known camera position.


DatasetGAN, a GAN developed by Nvidia, is then used to annotate automatically each of these generated images, down to the pixel level(semantic segmentation).
This is what allows Nvidia to animate 3D objects like the car, once converted from a 2D photo.


What is the DIB-R Tutorial about?
The DIB-R Tutorial which we can now find on Github is about showing you how the DIB-R differential renderer works, and how it can be used to recover 3D model structure and texture from multiple 2D images as a pure optimization problem.
But, more importantly, what it is not. It is not a tutorial on how you can generate 3D models from a single 2D image using the neural network that was described in the second part of the DIB-R paper. You will see later when we step through the code, that it is not using a neural network.
The DIB-R Paper
Now that, let’s just talk about the DIB-R paper in a bit of detail, as this will help to understand the DIB-R tutorial.
The problem of converting a 2D image to its original 3D scene is the inverse problem of traditional computer graphics, hence the name inverse graphics.
Easier said than done, inverse graphics is quite difficult because traditional rendering pipelines like OpenGL, DirectX were never designed to allow recovery of the 3D scene being rendered. These pipelines were developed to be efficient and they contain a lot of optimizations, which causes some of 3D scene information to be lost.
What is a Differential Renderer
I think it is worth talking about what a differential renderer is and why it is needed.
Let’s imagine we are trying to solve this computer vision problem ourselves, but not necessarily with Machine Learning.
A 2D photo is a projection of a 3D scene. A 3D scene is a collection of 3D meshes, vertices, faces, texture maps, and a light source, viewed from a camera or viewpoint. For simplicity, let’s limit our 3D scene to a single 3D object.
If we were able to recover the original 3D scene that produced the 2D photo, we should be able to verify it by projecting the given 3D object to 2D using the same viewpoint that was used to generate the input 2D photo.
Brute Force
In order to reconstruct our 3D object, a brute-force approach would be to calculate every possible combination of vertices, faces, light source, and texture which when projected to 2D should produce an equivalent image in 2D as the one given as input, as long as the camera position is the same. This is essentially a search problem.
But the problem with a brute-force attempt is that there are a gazillion, combinations of vertices, faces, texture maps, and lighting that can be created.
So we can’t brute-force our way out of this problem.
Gradient-based approach
Let’s try to find a smarter way!
How about we start with an initial mesh, for example, a sphere, which is topologically similar to the 3D object we are trying to recover, for example, a clock, and then we try to make changes so that we mould this sphere to be similar to the clock?
We can make changes at different levels:
- change input mesh geometry by moving vertices around
- change the colors in the texture
- change the input lighting
If you think about it, that’s similar to what a 3D modelling artist would do. They will always pick a base geometry similar to the 3D object what they are trying to reconstruct.
The key point is, if we make changes to the geometry of the sphere, then we expect the geometry to converge or diverge from the target geometry, and the same for the texture and light source.
To verify that we are converging, I mean, getting closer to the target shape, in this case a clock, at each step we need to project our moulded sphere to 2D using a similar viewpoint as the input 2D image and verify that we are getting closer.
Rasterization
But Houston, we have a problem, to convert from a 3D scene to 2D we need to use a graphics rendering pipeline.
In a traditional computer graphics pipeline, a rasterization technique is used to render a 3D scene onto a 2D scene.
During the process of projecting a 3D image to a 2D plane, rasterizing triangles, and shading pixels, there is a loss of information, due to the algorithms that are used in the graphics pipeline. The problem with these losses is that they introduce discontinuities in the images.
This means that often making minute changes to the geometry might not result in a different image at all. Or worse, the image will suddenly change leaving us farther from the target 2D image. This is a no… no…
Because of these two problems, we have no way to know in which direction to go in our search. And that makes recovering the original 3D scene from a 2D photo, very difficult.
Differential Renderer to the rescue
So it seems that we need to design our own rendering pipeline, aka differential renderer.
This new rendering pipeline will guarantee that for each change in the input 3D object, there is a guaranteed change in the projected 2D image pixels, and this change will be a gradual change for every pixel.
Furthermore, each generated pixel will have derivatives that can be used to determine, I mean, back-propagate, the original inputs that contributed to the final value of each pixel.
Luckily, we don’t have to reinvent the wheel. DIB-R is a differential renderer that we can use!
DIB-R — The differential renderer
DIB-R is a differential renderer that models pixel values using a differentiable rasterization algorithm. It has two methods of assigning pixel values. One for foreground pixels and another for background pixels.
Foreground Pixels
For foreground pixels, the paper says:
Here, in contrast to standard rendering, where a pixel’s value is assigned from the closest face that covers it, we treat foreground rasterization as an interpolation of vertex attributes[4]. For every foreground pixel we perform a z-buffering test [6], and assign it to the closest covering face. Each pixel is influenced exclusively by this face.
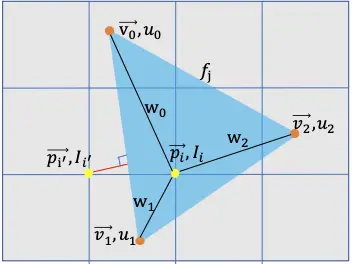
So in summary, foreground pixels are calculated as an interpolation of the nearest three adjacent vertices using and a weight for each vertice, where Ii is the pixel intensity.
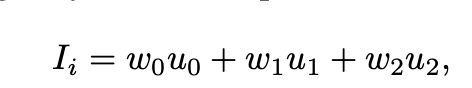
Background pixels
For background pixels, which are, pixels that are not covered by any face of the 3D object, the pixel value is calculated based on the distance from the pixel to the nearest face.
Other Differential Renderers
It is important to highlight that DIB-R is not the first and only differential renderer. It is an improved differential renderer which is based on the ideas of OpenDR, from 2014, and also SoftRas-Mesh which proposed a similar differential renderer to DIB-R.

How can we generate a 3D model and texture from a single image?
So I only mentioned the stuff we can see. What about the stuff we don’t see? Surely, if I only have a picture of the front of a clock, how can it figure out what is in the back of the clock?
The solution is by hallucination. Let me explain.
The only thing in machine learning that can imagine things at the moment is a GAN(generative adversarial network).
So it shouldn’t come as a surprise that we also can use GANs to generate 3D objects and a texture.
Without going into too much detail, the DIB-R paper, describes in the second part of the paper, using a GAN with encoder-decoder architecture to predict the vertex positions, geometry, colors/texture of a 3D model from a single image using 2D supervision, using the differential renderer.
Back to the DIB-R Tutorial
But the DIB-R tutorial doesn’t use a GAN nor any neural network. Instead, it’s just a simple demonstration of how we can use the DIB-R differential renderer, in conjunction with PyTorch to solve an optimization problem in regards to recovering 3D geometry and texture iteratively from multiple viewpoints of the same object, in this case, a clock.
Time to run the tutorial!
The purpose of the DIB-R tutorial is to show how to use DIB-R, the differential renderer when trying to reconstruct the 3D geometry and texture of a 3D object, like the clock, which is part of the kitchen dataset from Pixar. This dataset is a collection of 3D objects which you will normally find in a kitchen, which Pixar has kindly open-sourced.
The clock that you can find in the kitchen dataset was selected because it is a relatively simple object with no topological holes.
Generating Training Data
First, we use the Nvidia Kaolin app, to generate a dataset of 2D images of the clock, from different viewpoints, in this case, a total of 100 different viewpoints.
For each viewpoint, we generate an RGB image, a segmentation mask, and an additional metadata JSON file that contains the camera parameters, such as focal point, aperture, focal length, etc.
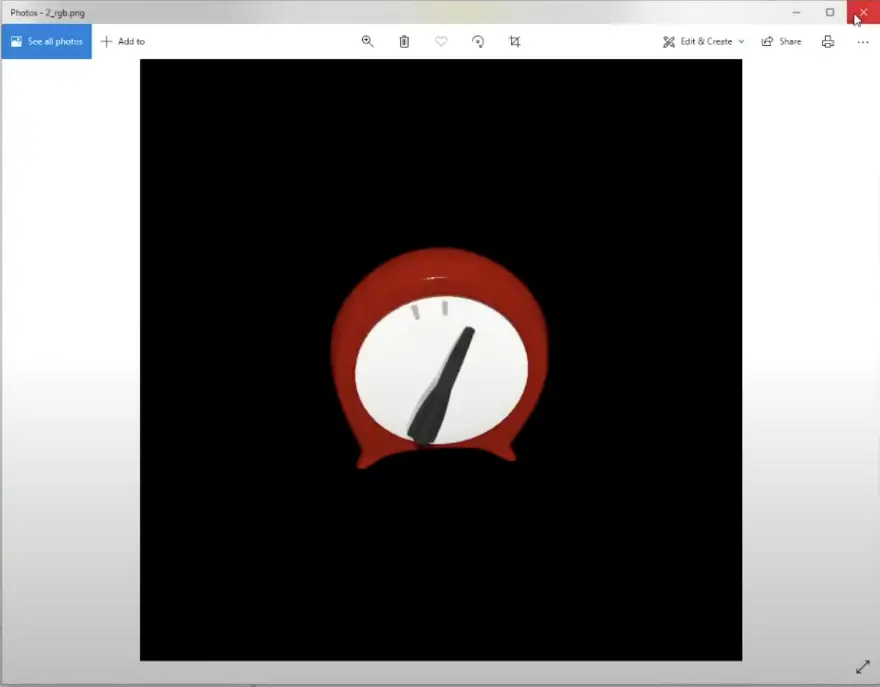

Loading the Training Data
To load the training data we use torch.utils.DataLoader, a class in PyTorch to load datasets into memory, ready to use for the GPU. Notice that we set pin_memory to True, which automatically will load the dataset into pinned memory, which will be faster to transfer to the GPU memory, once training starts.
Also, we use the kal.io.render.import_synthetic_view method to load each image in the training dataset, in addition, it loads the semantic mask file for each image and the metadata json containing the camera parameters.
num_views = len(glob.glob(os.path.join(rendered_path,'*_rgb.png')))
train_data = []
for i in range(num_views):
data = kal.io.render.import_synthetic_view(
rendered_path, i, rgb=True, semantic=True)
train_data.append(data)
dataloader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,shuffle=True, pin_memory=True)
Loading the Sphere Template
Next, we load a sphere in obj format. This sphere will be molded during the training, to look similar to the clock.
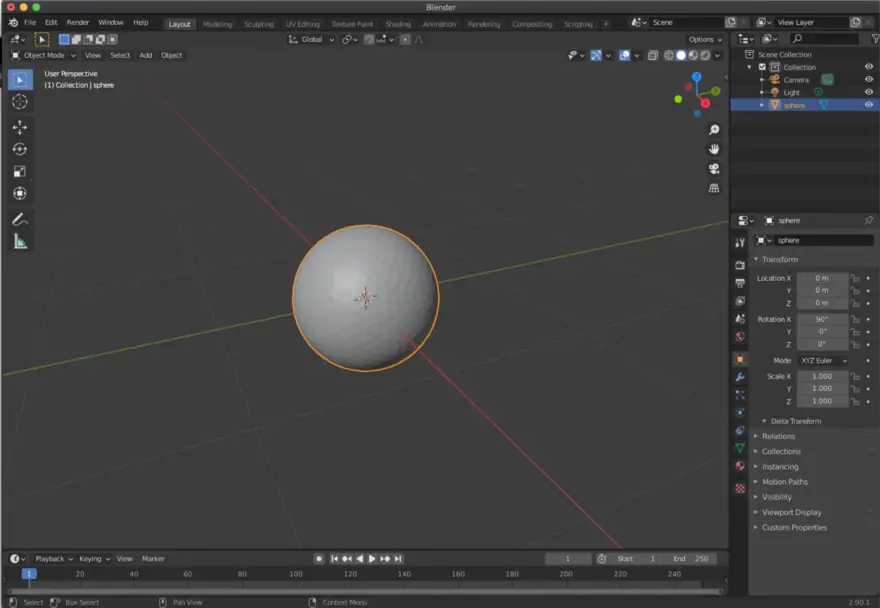
During the training, we are not going to change the topology of the sphere, e.g. add any holes.
Preparing the Losses and the Regularizer
Now in this section of the Jupyter notebook, we set up the loss functions. These loss functions have two purposes:
- To be used as a way to know how far off we are from the ground truth. Our ground truth will be the different views of the clock taken from a camera in different locations.
We use the Image L1 Loss, which is the absolute difference between the predicted image and the ground truth image.
Also, we calculate the mask loss, which is a measurement of how much the predicted soft_mask intersects(IoU) with the ground truth segmentation mask of our clock. - To be used as a regularizer, in order to penalize any geometry which has self-intersecting faces and to encourage smoothness. In this case, we use the Laplacian Loss and the flat loss. These are common smoothness regularizers used.
loss = (
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)


Left: Target Dolphin Center: 3D Reconstr. with Smoothness regularizer Right: w/out
Setting up the Optimiser
The tutorial picks Adam as the optimization algorithm used during training.
optim = torch.optim.Adam(params=[vertices, texture_map, vertice_shift],lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=scheduler_step_size,=scheduler_gamma)The Adam optimizer algorithm will be taking the vertices, the texture_map, and the vertice_shift as learnable parameters during training.
The vertice_shift seems to be a parameter that is used to shift all the vertices of the sphere during training.
Here I am guessing, it seems to me that every time you change the shape of the sphere, you shift the center. and that is why that at each step of the training, we call the recenter_vertices method that takes as input the vertices and the vertices_shift parameters.
def recenter_vertices(vertices, vertice_shift):
"""Recenter vertices on vertice_shift for better optimization"""
vertices_min = vertices.min(dim=1, keepdim=True)[0]
vertices_max = vertices.max(dim=1, keepdim=True)[0]
vertices_mid = (vertices_min + vertices_max) / 2
vertices = vertices - vertices_mid + vertice_shift
return verticesTraining
In the training, the tutorial runs for a total of 40 epochs. Each epoch has 100 steps, which is the number of views that we have taken for the clock.
In epoch 0, we start with a sphere, which we loaded earlier in the notebook. The sphere vertices are stored in vertices, and the initial texture map for the sphere is stored in texture_map.
In each step we render the 3D sphere, using DIB-R the differential renderer, which is being molded, to 2D with the texture applied to it, using the same camera position and parameters as the camera used for the ground truth clock.
Then at the end of each step, we calculate the losses:
loss = (
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)And finally we update the mesh:
### Update the mesh ###
loss.backward()
optim.step()These two lines of code are essential:
- loss.backward() calculates the gradients, I mean the changes in values for each of the parameters that we are optimizing. And optim.step() updates the parameters according to these gradients. This is what it is meant when saying that back-propagation.
Note that during training, for each epoch we are also taking a snapshot of how the sphere looks like over time. We will visualise it later using the Nvidia Kaolin App.
Visualise Training
The last block of code is just to show what the final shape looks like, for the sphere after it is molded to look like a clock.
Once you run it you should get a similar result!


At this stage, we should be able to view a timelapse of the training using the Nvidia Kaolin App. Watch my video for this tutorial to see how to do that.
Hope this article was useful and that you understand now why a differential renderer is needed and why it is so important for 3D Deep Learning.
Happy Coding!
RESOURCES
Recommended Courses for Data Science
- Learn Python for Beginners 👉🏼 Python for Everybody
- Learn Deep Learning with Andrew Ng 👉🏼 Neural Networks and Deep Learning by Andrew Ng
- Learn Data Science with Coursera Plus 👉🏼 Coursera Plus For Data Science
Research Papers
Yuxuan Zhang, Wenzheng Chen, Huan Ling, Jun Gao, Yinan Zhang, Antonio Torralba, Sanja Fidler
IMAGE GANS MEET DIFFERENTIABLE RENDERING FOR INVERSE GRAPHICS AND INTERPRETABLE 3D NEURAL RENDERING
https://arxiv.org/pdf/2010.09125.pdf
Wenzheng Chen, Jun Gao*, Huan Ling*, Edward J. Smith*, Jaakko Lehtinen, Alec Jacobson, Sanja Fidler
Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer
https://nv-tlabs.github.io/DIB-R/
Yuxuan Zhang, Huan Ling, Jun Gao, Kangxue Yin, Jean-Francois Lafleche, Adela Barriuso, Antonio Torralba, Sanja Fidler
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
https://arxiv.org/pdf/2104.06490.pdf
Shunyu Yao, Tzu Ming Hsu, Jun-Yan Zhu, Jiajun Wu, Antonio Torralba, Bill Freeman, and Josh Tenenbaum
3d-aware scene manipulation via inverse graphics. In Advances in neural information processing systems,
https://arxiv.org/pdf/1808.09351
Matthew M. Loper and Michael J. Black
OpenDR: An Approximate Differentiable Renderer
https://files.is.tue.mpg.de/black/papers/OpenDR.pdf
Paul Henderson, Vittorio Ferrari
Learning to Generate and Reconstruct 3D Meshes with only 2D Supervision
https://arxiv.org/pdf/1807.09259.pdf
Shunyu Yao, Tzu Ming Hsu, Jun-Yan Zhu, Jiajun Wu, Antonio Torralba, Bill Freeman, and Josh Tenenbaum
3d-aware scene manipulation via inverse graphics. In Advances in neural information processing systems,
https://arxiv.org/pdf/1808.09351
Websites
Nvidia Kaoolin Github Page
https://github.com/NVIDIAGameWorks/kaolin