By now we are all aware of the data center in Strasbourg, France that completely burned down.
This data center was owned by OVH.
OVH is Europe’s largest cloud computing and web hosting company with headquarters in France.
Mind that, a modern datacenter is not supposed to burn down because of all the safety features that it is supposed to have. But for some reason, those safety measures did not work.
It is sad to see such a disaster happen, but thankfully there were no injuries or fatalities.
Complete Data Loss
Very sadly, plenty of OVH customers have lost all their data. This is the worst-case scenario and a stark reminder that the worst-case scenario does happen. You simply can’t ignore it.
As a business, it should not be possible to lose all your data because of an incident like this. Losing all your data can put you out of business.
It is vital to have a disaster recovery and business continuity plan in place. And it better work.
In this video, I am going to give you some ideas on how you can integrate disaster recovery and business continuity planning into the design of your Cloud Solution. I will focus mainly on GCP services but you can easily translate the ideas in this video to AWS or Azure.
Business Continuity Planning
As a business, you need to be prepared for the eventuality that a major incident can hit at any time. It could be a data center burning down, a simple hardware failure, a flood, a Denial of Service attack, a network failure, a data breach, or even a problem with your web hosting provider denying you service, …
So before designing any cloud solution, it is a good idea to create a risk matrix specific to your business and Cloud Solution
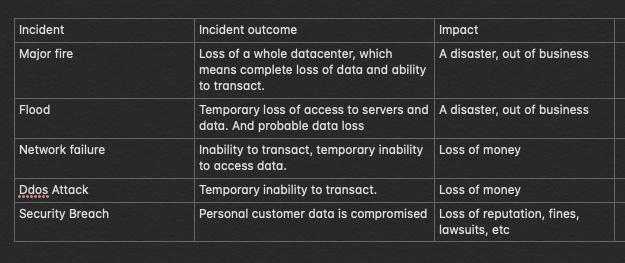
In this fictitious and shortened risk matrix for a fictitious business, I list the potential list of incidents that can occur, the outcome of such an incident occurring, and the impact on the business and its customers. I didn’t add a column for likelihood, because you should keep this list honest. The risks you list however unlikely they seem, are likely to happen over a long period of time. It is easy to fall into the temptation that just because something is very unlikely to happen, it will never happen. But the opposite is the truth.
With that in mind then we can make appropriate and cost-effective decisions when designing a resilient cloud solution.
Let’s start with some key decisions.
What Database to use
In GCP there are many database solutions available. You can host your own database, or you can use a managed database solution like, for instance, Cloud SQL, that is if you are looking for a relational database.
Cloud SQL is a managed database solution that offers three flavors of a relational database: Mysql, PostgreSQL, and SQLServer.
Regardless of the flavor you pick, you will have a managed database with automatic incremental backups, with a default retention period of seven days, and with data, encryption switched on by default. You can increase the backup retention period, or decrease it according to your requirements. The backups are automatically stored by default stored in multiple regions.
Cloud Agnostic
If being cloud-agnostic is important to your organization then CloudSQL is awesome because it uses the standard database solutions of Mysql, Postgresql, and Microsoft SQL Server, which makes migration to/away from CloudSQL a breeze.
High Availability
If making sure that your application is available at all times is important, if you pay a “little” bit extra, then you also have the option of creating a regional Cloud SQL database, that has replicas across zones within a region. Each Zone in a region is by definition a separate physical data center within a region. This means that in case the primary instance goes offline, Cloud SQL will immediately failover to a standby instance. With this setup any writes to the primary instance will be propagated automatically to the standby instances, ensuring that all replicas are consistent.
Multi-regional Failover
But, what happens if the whole region goes down? It does happen, for example in the case of OVH’s Strasbourg fire, the fire in one data center did cause the failure in the other adjacent data centers. There are other plausible scenarios, but out of scope here.
In that case, there is the option to set up a read replica in another region which in case of a DR event can be promoted to the primary instance. You can recover fairly quickly but it is not automatic and will likely incur some level of downtime and some data loss, depending on the settings you pick.
Cloud Spanner
IF data loss and downtime are not at all acceptable in the unlikely event of a regional failure, then you might need to look at another solution such as Cloud Spanner. Cloud Spanner is a cross-regional database service with transactional consistency across regions which can handle billions of rows and with five-nines of availability. It is all great, but then you do need to consider the risk of vendor lock-in and whether that is acceptable to your organization.
Storage Solutions — Standard Persistent disks and Regional Persistent disks
If you must manage your own database, then you will need to take on board a lot more work. You will of course want to have all the backups in place, high availability, and redundancy.
Other than that, you probably don’t want to lose your database just because a hard drive failed. This does happen often!
So you should consider carefully the storage solution for your database. You probably don’t want to use a zonal standard PD if you are planning to run the database as a single instance. In that case, at a minimum, you should use a regional standard persistent disk. A regional persistent disk is replicated across the zones within a region. If you decide to setup a database cluster, maybe zonal standard PD is ok, as long as you set up each node in a different zone within a region and using a separate persistent disk. If you need fast writes and reads, go with an SSD PD.
If you have ever tried to run a Mysql Cluster before, on your own, then you will know that clusters are high maintenance and prone to failure, especially if connectivity between cluster nodes is less than excellent. But, it is a must if you need high availability.
Zonal standard PD | Regional standard PD | Zonal balanced PD | Regional balanced PD | Zonal SSD PD | Regional SSD PD | Local SSDs | Cloud Storage buckets | |
|---|---|---|---|---|---|---|---|---|
| Storage type | Efficient and reliable block storage | Efficient and reliable block storage with synchronous replication across two zones in a region | Cost-effective and reliable block storage | Cost-effective and reliable block storage with synchronous replication across two zones in a region | Fast and reliable block storage | Fast and reliable block storage with synchronous replication across two zones in a region | High performance local block storage | Affordable object storage |
| Minimum capacity per disk | 10 GB | 200 GB | 10 GB | 10 GB | 10 GB | 10 GB | 375 GB | n/a |
| Maximum capacity per disk | 64 TB | 64 TB | 64 TB | 64 TB | 64 TB | 64 TB | 375 GB | n/a |
| Capacity increment | 1 GB | 1 GB | 1 GB | 1 GB | 1 GB | 1 GB | 375 GB | n/a |
| Maximum capacity per instance | 257 TB* | 257 TB* | 257 TB* | 257 TB* | 257 TB* | 257 TB* | 9 TB | Almost infinite |
| Scope of access | Zone | Zone | Zone | Zone | Zone | Zone | Instance | Global |
| Data redundancy | Zonal | Multi-zonal | Zonal | Multi-zonal | Zonal | Multi-zonal | None | Regional, dual-regional or multi-regional |
| Encryption at rest | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Custom encryption keys | Yes | Yes | Yes | Yes | Yes | Yes | No | Yes |
| Machine type support | All machine types | All machine types | Most machine types | Most machine types | Most machine types | Most machine types | Most machine types | All machine types |
Data Security
I am not going to cover in-depth data security, but it should be at the top of your mind.
If you must collect sensitive information, then think of a strategy where even if your database security is breached, it will be of little value to hackers.
This will ensure that you keep yourself honest about what personal data you must collect and how you store it.
Without proper control, it is easy for developers to just keep adding extra fields to your database and before you know it, your previously squeaky clean database holds sensitive personal information that is not properly protected and segregated.
Some level of monitoring with machine learning should be considered, to prevent serious data breaches. For instance, an ML Algorithm should be pretty good at detecting if a database field holds personal information or not.
High Availability with Google Kubernetes Engine
If you set up a database with high availability and then find that your web application is unavailable because the server burned down, that would still cost you a lot of money in lost trade.
Therefore you must also have high availability at the application level. If you a
re using Google Kubernetes. That can be easily achieved with a Regional Kubernetes Cluster, which has nodes running in different zones. Zones, are basically different physical data centers within the same geographic region e.g. Zurich.
[/et_pb_text][/et_pb_column] [/et_pb_row] [/et_pb_section]