Google Cloud SQL comes with out-of-the-box functionality that meets the most strict requirements out there for high availability, scalability, and disaster recovery.
I will be going through these features at a high level, and as a bonus at the end, I will show you how you can easily create a Cloud SQL instance with high availability enabled and automatic backups configured.
What is Cloud SQL?
Cloud SQL is a managed database service provided by Google that offers MySQL, SQL Server, and PostgreSQL as managed database options. What this means is that any application that works with either MySQL, SQL Server, or PostgreSQL, will also work with Cloud SQL.
High Availability with Cloud SQL
A Cloud SQL instance that is configured with HA is also known as a Regional Cloud SQL instance. Within a region, the Cloud SQL database HA has a primary zone and a secondary zone.

The primary zone is where the primary instance of Cloud SQL is located. And the secondary zone is for the standby Cloud SQL instance.
We can configure which zone to use for the primary instance, but we have no control over the zone where the standby instance resides. Both zones always reside inside the same region.
Cloud SQL HA Replication
All replication between the primary instance and the standby instance done synchronously.
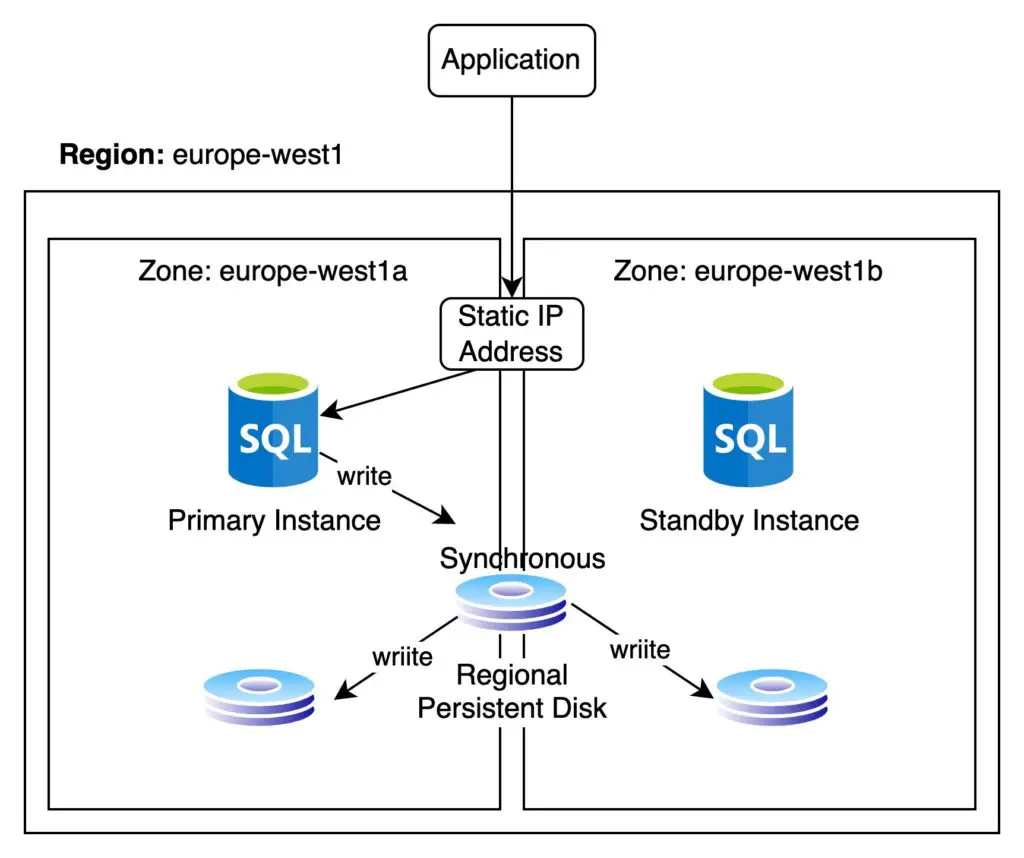
With synchronous replication, any transaction in the database needs to wait until it is committed in both the primary and secondary instance. In this way we are ensuring that the two database instances are in sync at all times. This replication is done with help from a regional persistent disk.
For Read replicas, the replication is done asynchronously, which means that when a database transaction is first committed to the primary database instance first and then copied to the standby instance as soon as possible. In this case, the standby instance will be a near real-time copy of the database in the primary instance.
It is important to note that the standby instance is not available to receive traffic. That is unless there is a failover in case the primary database instance becomes unavailable. If you are looking to scale out your database to support higher levels of traffic, you need to set up read replicas. More on that later.
Cloud SQL HA Failover
In order to know whether a Primary instance is alive and well, Cloud SQL writes to a system database a heartbeat signal every second. If multiple heartbeats are not detected, after approximately 60 seconds, failover is started to the standby instance. The static IP address that points to the primary instance will be reassigned to the standby instance. The standby instance becomes the primary instance and the failed primary instance is eventually shut down and destroyed.
A new standby instance is created in an alternative available zone within the same region.
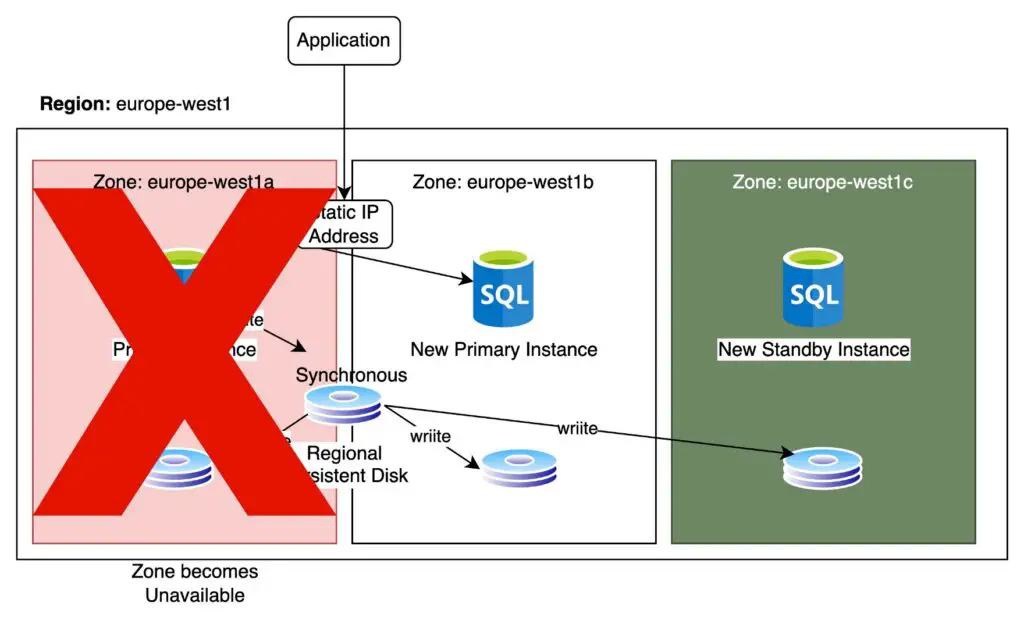
The whole process of failover will typically last for a couple of minutes from beginning to end. During this time the Cloud SQL database will be unavailable. No connection details need to change in the process of failover, but any existing database connections will automatically close in the event of a failover.
Maintenance Updates on Cloud SQL Instances
Even if you pick the HA configuration in PostgreSQL, there will be weekly maintenance updates on the Cloud SQL instance. This means that there will be downtime of approximately 2–3 minutes. each week. But at least it is possible to configure the maintenance window.
Cloud SQL Pricing with HA
When considering the cost of Cloud SQL with high availability enabled, you need to double the cost of a single Cloud SQL instance by two.
Scaling with Cloud SQL
It is ok to deploy a small-scale application into a single database server. However, if your application grows, you will need to increase capacity for more database queries by increasing the number of database instances, i.e. horizontally scaling.
Master-Slave Replication
Cloud SQL supports the option of creating a database cluster with a Master-Slave setup, where you have a single read/write database instance, coupled with one or more read replicas. Read Replicas can be within the same GCP region or in a separate GCP region. The consequence of that is that the read replica will lag a bit behind.
Sharding
In case of applications that require multiple read/write database instances, then, the best option is to use Sharding using Cloud SQL and ProxySQL.
With Sharding we split the data between separate database instances, using some logical split rule, and then we route the queries to the correct database instance using a query router or at the application level.
Cloud SQL Backups
By default Cloud SQL does an automated daily backup of of the database and retains up to 7 of the last backups. This number can be increased up to 365.
Only the oldest backup contains a full copy of the database, and from that point all subsequent backups are incremental backups.

To setup the correct backup strategy it will be important to have recovery goals in place, such s the recovery point objective(RPO) and a recovery time objective(RTO) time in place.
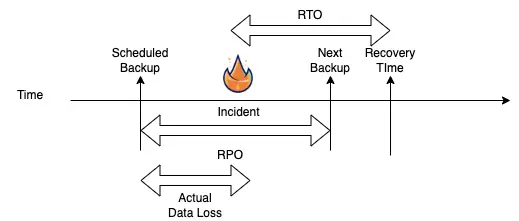
What is a Recovery Point Objective?
A recovery point objective is the amount of time where information can be lost after the last backup. Typically when backing up a database, the database will continue to write data to disk, but these will only be part of the next backup. If there is an incident during this period then the RPO will be the maximum amount of time where data loss will occur.
How to set the correct Recovery Point Objective?
Having the correct RPO will depend on the business criticality of the data and how frequently it changes. If data hardly changes, you can set a higher RPO(e.g. 1 day), if data changes very often, then the RPO should be much smaller, perhaps measured in minutes rather than days.
What is the Recovery Time Objective?
When an incident occurs and you are required to restore data from the last available backup, it will take time. Based on your requirements you should set the maximum amount of time that it is tolerable, i.e. the Recovery Time Objective(RTO) where your application can be offline whole you restore the data from the last backup and get the application up and running again.
Point-in-time Recovery in Cloud SQL
The good news is that if you enable Point-in-Time recovery then data loss can be completely prevented even for the data not available in the last backup. This is because point-in-time recovery relies on the transactional database logs which can be used to rebuild the database up to the point in time when the data loss occurred.
Incidentally, if you enable HA in Cloud SQL, you will have to also enable point-in-time recovery.
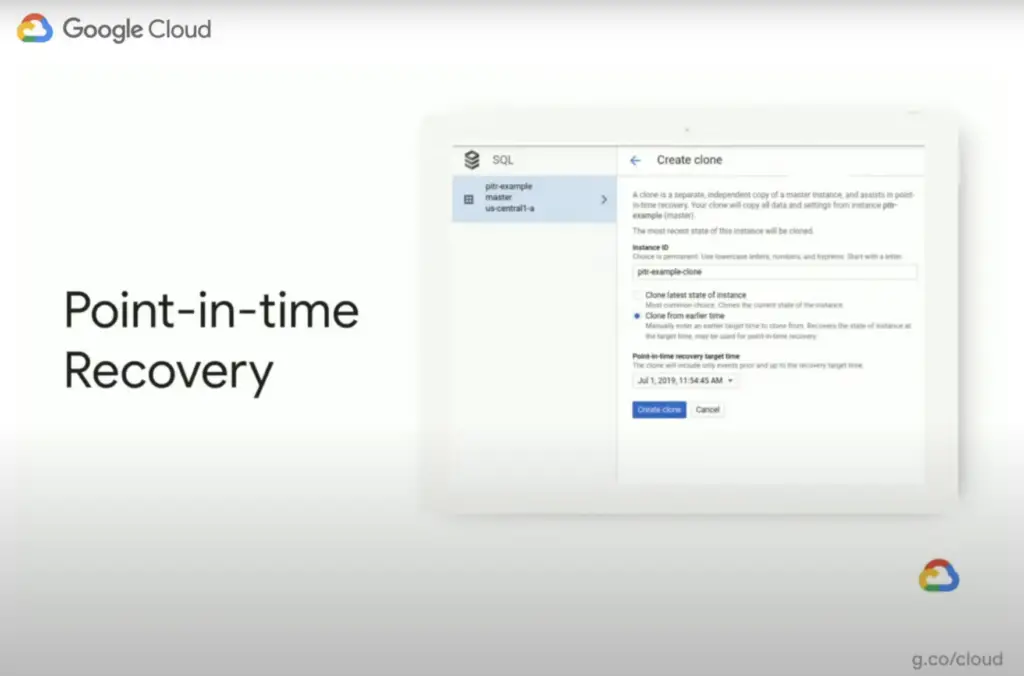
Point-in-time Recovery to recover from user errors
Point-in-time recovery is not just useful for situations where there is a disaster. Far more likely is accidental data loss or data corruption, where for instance one or more tables are accidentally deleted. In this case, using point-in-recovery Google allows you to create a clone of the database using the selected point in time, up to the last 7 days.
Note that one of the limitations or you can also call it a feature, of point-in-time recovery, is that a new database instance will be created. You can’t perform PITR directly on the database instance.
Recommendations for Disaster Recovery and High Availability
If you want to have a robust, highly available and scalable Cloud SQL database, then it is recommended that you have in place:
- enable automated daily backups and point-in-time recovery
- enable in-region high availability (synchronous)
- in-region and cross-region replication (asynchronous)