When running big machine learning training jobs using neural networks, you need a GPU. And let’s be honest, GPUs are expensive and hard to get nowadays with the chip shortage! So it is unlikely that you will have plenty of spare GPUs lying around.
This is why it makes sense to rent GPUs on the Cloud. But since GPUs are expensive, you don’t want to hold on to them any longer than necessary!
This is why running big machine learning jobs on Google Kubernetes Engine makes sense. GKE gives you access to all kinds of machine types. From the humble VM with 1 vCPU to a monster-sized VM with dozens of vCPUs and with access to state-of-the-art GPUs like the Nvidia A100.
What makes Kubernetes attractive is that you can scale up or down the number of resources depending on how heavy your workloads are.
Kubernetes also has an excellent Jobs API which you can make use of to distribute jobs across a large number of nodes.
And, more importantly, you don’t have to reinvent the wheel. To run machine learning workflows you can use for instance the popular kubeflow open source machine learning framework which is designed for this specific purpose.
GPUs are expensive
But GPUs are still expensive!
Just to give you an idea of the prices involved in renting a GPU let’s take a look at the state of the art Nvidia A100 pricing in Google Cloud:
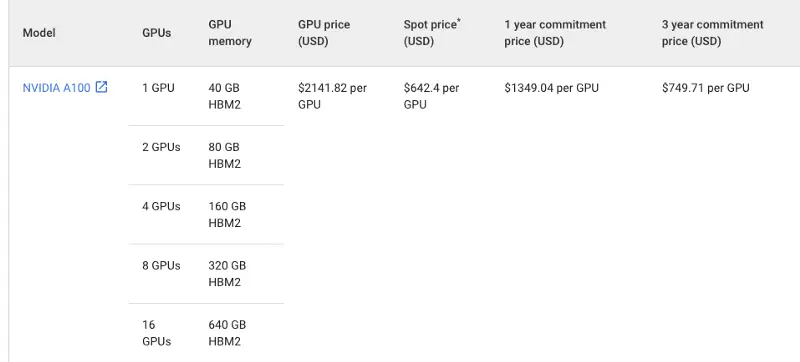
It is a pretty high cost at $2141.82 per GPU per month. Yes, you can reduce the cost significantly by committing to a longer-term use from 1 year to 3 years. But that hardly works for most!
What if there is a way to borrow the same GPU for 60-90% less?
Yes, you guessed it right. There’s a way with Spot VMs.
What’s the catch with Spot VMs?
When it sounds too good to be true, it probably is, right?
The catch is that the Spot VM with that shiny expensive Nvidia A100 can be taken off you at any time with very little warning. But then again, instead of paying $2140 USD/month, you only pay $642/month($0.88/hour)?
Unlike Preemptible VMs which can be used for a maximum of 24h only, Spot VMs have no time limits.
Spot prices are dynamic
I know that I mentioned exact prices, but Spot prices do change at least once per month. So take the numbers I just mentioned with a pinch of salt. Also bear in mind that not all regions in GCP have GPUs available. On average you should expect to pay 60–91% less for a GPU with spot pricing than a full-priced GPU. And you only have to pay for what you use.
Resilience/Redundancy/Parallelism
To take advantage of Spot VMs and GKE you need to write your own machine learning jobs in a way that they can be distributed across multiple nodes and multiple GPUs and are able to cope with frequent failure. So parallelism, distribution of training, and restarting jobs on failure will be key to being able to take advantage of Spot VMs.
The code for creating a GKE Cluster with Spot VMs using Terraform
I am going to show you how to create a GKE Cluster with Spot VMs automatically using Terraform.
At the time of writing, the ability to create a node pool with Spot VMs is still a preview feature. So in order to create a cluster with Spot VMs we need to unlock some beta features in Google’s Terraform module.
To do that you will see in the file terraform/gke.tf the following source code:
module "gke" {
depends_on = [google_service_account.gke-sa, google_project_service.kubernetes, google_project_service.compute, google_project_service.iam]
source = "terraform-google-modules/kubernetes-engine/google//modules/beta-public-cluster"
version = "19.0.0"
....
}We are using a beta submodule called beta-public-cluster which enables us to create a node pool with a Spot VM.
And in the terraform/providers.tf file you will see:
provider "google" {
credentials = var.gcp_credentials
project = var.gcp_project_id
region = var.gcp_region
}
provider "google-beta" {
credentials = var.gcp_credentials
project = var.gcp_project_id
region = var.gcp_region
}You need both the google provider and the google-beta provider setup.
Now let’s go back to terraform/gke.tf and specifically to the node_pool section:
module "gke" {
...
node_pools = [
{
name = var.gke_default_nodepool_name
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
initial_node_count = 1
},
{
name = "ephemeral-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
preemptible = true
},
{
name = "spot-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
spot = true
}
]For a standard node pool with full-priced VMs, no flags are needed.
Controlling the machine type for each Worker Node in Kubernetes
Note that the machine_type controls the VM that is used for each worked node. In the example code above I am using a cheap VM. But if I was feeling rich I could opt to use a2-megagpu-16g as the machine type instead. This would give me access to a VM with 16 GPUs and over 1TB of memory. If I was trying to decode the meaning of life, that’s the type of machine type I would go for!
Creating a node pool with Preemptible VMs
To create a node pool with preemptible VMs all that is required is to add a flag to the node pool:
{
name = "ephemeral-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
preemptible = true
},Creating a node pool with Spot VMs
To create a node pool with Spot VMs, it is as easy as just adding the flag spot = true
{
name = "spot-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
spot = true
}variables.auto.tfvars
gcp_credentials = "../creds/gcp-service-account.json"
gcp_project_id = "<YOUR-PROJECT-ID>"
gcp_region = "us-west1"
gcp_zone = "us-west1-a"
gke_default_nodepool_name= "<DEFAULT-NODEPOOL-NAME>"
gke_cluster_name = "<CLUSTER-NAME>"
gke_network = "<VPC-NETWORK-NAME>"
gke_subnetwork = "<VPC-SUBNETWORK-NAME>"
gke_zones = ["us-west1-a"]
gke_sa_name= "<GKE_SERVICE_ACCOUNT_NAME>"Now that we have taken a look at the source code, let’s create a GKE Cluster with spot vms and preemptible vms:
terraform initAnd that’s it! I hope you found this article useful and I hope you save a lot of money on your workloads with Spot VMs.
Resources
Source Code
https://github.com/armindocachada/terraform-gke-spot-vm-example
Google Cloud Spot VMs
https://cloud.google.com/spot-vms
Related Article
How I migrated all my websites to Google Kubernetes Engine on the cheap using Spot VMs